Components and Functions
Top-level functions
Prodigy provides the following top level utilities for writing your own scripts
and recipes. To use them, import the prodigy module at the top of your file.
prodigy.serve function
Serve a Prodigy recipe and start the web app from Python. Does the same as the
prodigy command on the command line. Since you’re already in a Python script,
you don’t have to use the -F flag to serve custom recipes (and point that to
yet another Python file). Instead, you can just import the recipe function or
keep the recipe function in the same file as the call to prodigy.serve. The
@prodigy.recipe decorator will take care of making it available.
prodigy.serve("ner.manual ner_news_headlines en_core_web_sm ./news_headlines.jsonl --label PERSON,ORG", port=9000)
| Argument | Type | Description |
|---|---|---|
command | str | The full recipe command without “prodigy”. See the recipe documentation for examples. |
*args | - | Deprecated: Recipe-specific arguments, in the same order as the recipe function arguments. Only available for backwards-compatibility. |
**config | - | Additional config parameters to overwrite the project-specific, global and recipe config. |
prodigy.recipe decorator
Decorator that transforms a recipe function into a
Prodigy recipe. The decorated function needs to return a
dictionary of recipe components or a Controller. The decorator’s first
argument is the recipe name, followed by a variable number of argument
annotations, mapping to the arguments of the decorated function. This lets you
execute the recipe with Prodigy.
from prodigy.components.stream import get_stream
@prodigy.recipe(
"example",
dataset=("Dataset to save annotations to", "positional", None, str),
source=("Source data to load", "positional", None, str),
view_id=("Annotation interface to use", "option", "v", str)
)
def example(dataset, source, view_id="text"):
stream = get_stream(source)
return {
"dataset": dataset,
"view_id": view_id,
"stream": stream
}
| Argument | Type | Description |
|---|---|---|
name | str | Unique recipe name. Used to register the recipe and call it from the command line or via prodigy.serve. |
**annotations | - | Argument annotations in Plac style, i.e. argument name mapped to tuple of description, style, shortcut and type. See here for details. |
| RETURNS | callable | Recipe function. |
prodigy.get_recipe function
Get a recipe for a given name.
| Argument | Type | Description |
|---|---|---|
name | str | The recipe name. |
path | str / Path | Optional path to recipe file. |
| RETURNS | The recipe function. |
prodigy.set_recipe function
Register a recipe function with a name. Also adds aliases with - and _
swapped. When you use the @recipe decorator, the recipe will be set
automatically.
| Argument | Type | Description |
|---|---|---|
name | str | The recipe name. |
func | callable | The recipe function. |
prodigy.get_config function
Read and combine the user configuration from the available prodigy.json config
files. Helpful in recipes to read off database settings, API keys or entirely
custom config parameters.
config = prodigy.get_config()
theme = config["theme"]
| Argument | Type | Description |
|---|---|---|
| RETURNS | dict | The user configuration. |
prodigy.get_stream function
Get an iterable stream of tasks. This function is also used in recipes that
allow streaming data from a source standard input. If a loader ID is set,
Prodigy will look for a matching loader, and try to load the source. If the
source is a file path or Path-like object, Prodigy will try to guess the
loader from the file extension (defaults to "jsonl"). If the source is set
to "-", Prodigy will read from standard input, letting you pipe data forward
on the command line.
stream = prodigy.get_stream("/tmp/data.jsonl")
stream = prodigy.get_stream("/tmp/myfile.tmp", loader="txt")
stream = prodigy.get_stream("/tmp/data.json", input_key="text", skip_invalid=False)
| Argument | Type | Description |
|---|---|---|
source | str | A text source, e.g. a file path or an API query. Defaults to "-" for sys.stdin.New: 1.10 Also supports dataset: syntax to load from an existing dataset, e.g. "dataset:my_set" to use data from my_set as the input. |
api | str | Deprecated: ID of an API to use. |
loader | str | ID of a loader, e.g. "json" or "csv". |
rehash | bool | Rehash the stream and assign new input and task IDs. |
dedup | bool | Deduplicate the stream and filter out duplicate input tasks. |
input_key | str | Optional input key relevant to this task, to filter out examples with invalid keys. For example, 'text' for NER and text classification projects and 'image' for image projects. |
skip_invalid | bool | If an input key is set, skip invalid tasks. Defaults to True. If set to False, a ValueError will be raised. |
| RETURNS | iterable | An iterable stream of tasks produced by the loader. |
If the source is an iterable stream itself – e.g. a generator or a list –
get_stream will simply return the stream. This is useful if you’re calling an
existing recipe function from Python – for example, in your custom recipe – and
want to use an already loaded stream.
prodigy.get_loader function
Get a loader ID from an ID or guess a loader ID based on a file’s extension.
loader = prodigy.get_loader("jsonl") # JSONL
loader = prodigy.get_loader(file_path="/tmp/data.json") # JSON
| Argument | Type | Description |
|---|---|---|
loader_id | str | ID of a loader, e.g. 'jsonl' or 'csv'. |
file_path | str / Path | Optional file path to allow guessing loader from file extension. |
| RETURNS | callable | A loader. |
prodigy.set_hashes function
Set hash IDs on a task based on the task properties. This is usually done by Prodigy automatically as the stream is processed by the controller. However, in some cases, you may want to take care of the hashing yourself, to implement custom filtering.
Input hashes are based on the input data, like the text, image or HTML. Task keys are based on the input hash, plus optional features you’re annotating, like the label or spans. This allows Prodigy to distinguish between two tasks that collect annotations on the same input, but for different features – for example, two different entities in the same text.
from prodigy import set_hashes
stream = (set_hashes(eg) for eg in stream)
stream = (set_hashes(eg, input_keys=("text", "custom_text")) for eg in stream)
| Argument | Type | Description |
|---|---|---|
task | dict | The annotation task to set hashes on. |
input_keys | tuple | Dictionary keys to consider for the input hash. Defaults to ("text", "image", "html", "input"). |
task_keys | tuple | Dictionary keys to consider for the task hash. Defaults to ("spans", "label", "options"). |
ignore | tuple | Dictionary keys (including nested) to ignore when creating hashes. Defaults to ("score", "rank", "model", "source", "_view_id", "_session_id"). |
overwrite | bool | Overwrite existing hashes in the task. Defaults to False. |
| RETURNS | dict | The task with hashes set. |
prodigy.get_schema function
Get the JSON schema for a given view_id. This is
the schema that Prodigy will validate against when you run a recipe. The JSON
schemas describe the properties and types needed in order for an interface to
render your task. The very first batch of the stream is validated before the
server starts. After that, tasks in the stream are validated before they’re sent
out to the web app. To disabled validation, set "validate": false in your
Prodigy config.
Validation is powered by pydantic,
so if you want to implement your own validation of Prodigy tasks and
annotations, you can set json=False and receive the pydantic model.
schema = prodigy.get_schema("text")
Example output{
"title": "TextTask",
"type": "object",
"properties": {
"meta": { "title": "Meta", "default": {}, "type": "object" },
"_input_hash": { "title": " Input Hash", "type": "integer" },
"_task_hash": { "title": " Task Hash", "type": "integer" },
"_view_id": {
"title": " View Id",
"enum": ["text", "classification", "ner", "ner_manual", "pos", "pos_manual", "image", "image_manual", "html", "choice", "diff", "compare", "review", "text_input", "blocks"]
},
"_session_id": { "title": " Session Id", "type": "string" },
"text": { "title": "Text", "type": "string" }
},
"required": ["_input_hash", "_task_hash", "text"]
}
| Argument | Type | Description |
|---|---|---|
view_id | str | One of the available annotation interface IDs, e.g. ner. |
json | bool | Return the schema as a JSON schema. Defaults to True. If False, the pydantic model is returned. |
| RETURNS | dict | The expected JSON schema for a task rendered by the interface. |
prodigy.log function
Add an entry to Prodigy’s log. For more details, see the docs on debugging and logging.
prodigy.log("RECIPE: Starting recipe custom-recipe", locals())
| Argument | Type | Description |
|---|---|---|
message | str | The basic message to display, e.g. “RECIPE: Starting recipe ner.teach”. |
details | - | Optional details to log only in verbose mode. |
Preprocessors
Preprocessors convert and modify a stream of examples and their properties, or
pre-process documents before annotation. They’re available via
prodigy.components.preprocess.
split_sentences function
Use spaCy’s sentence boundary detector to split example text into sentences,
convert the existing "spans" and their start and end positions accordingly and
yield one example per sentence. Setting a min_length will only split texts
longer than a certain number of characters. This lets you use your own logic,
while still preventing very long examples from throwing off the beam search
algorithm and affecting performance. If no min_length is set, Prodigy will
check the config for a 'split_sents_threshold' setting.
| Argument | Type | Description |
|---|---|---|
nlp | spacy.language.Language | A spaCy nlp object with a sentence boundary detector (a custom implementation or any model that supports dependency parsing). |
stream | iterable | The stream of examples. |
text_key | str | Task key containing the text. Defaults to 'text'. |
batch_size | int | Batch size to use when processing the examples with nlp.pipe. Defaults to 32. |
min_length | int | Minimum character length of text to be split. If None, Prodigy will check the config for a 'split_sents_threshold' setting. If False, all texts are split, if possible. Defaults to False. |
| YIELDS | dict | The individual sentences as annotation examples. |
from prodigy.components.preprocess import split_sentences
import spacy
nlp = spacy.load("en_core_web_sm")
stream = [{"text": "spaCy is a library. It is written in Python."}]
stream = split_sentences(nlp, stream, min_length=30)
split_spans function
Split a stream with multiple spans per example so that there’s one span per task.
| Argument | Type | Description |
|---|---|---|
stream | iterable | The stream of examples. |
labels | list | Only create examples for entities of those labels. If None, all entities will be used. |
| YIELDS | dict | The annotation examples. |
add_tokens function
Tokenize the incoming text and add a 'tokens' key to each example in the
stream. If the example has spans, each span is updated with a "token_start"
and "token_end" key. This pre-processor is mostly used in manual NER
annotation to allow entity annotation based on token boundaries.
| Argument | Type | Description |
|---|---|---|
nlp | spacy.language.Language | A spaCy nlp object with a tokenizer. |
stream | iterable | The stream of examples. |
skip | bool | Don’t raise ValueError for mismatched tokenization and skip example instead. Defaults to False. |
overwrite | bool | New: 1.9.7 Overwrite existing "tokens". Defaults to False. |
use_chars | bool | New: 1.10 Split tokens into single characters and add one entry per character. Defaults to False. |
| YIELDS | dict | The annotation examples with added tokens. |
from prodigy.components.preprocess import add_tokens
import spacy
nlp = spacy.load("en_core_web_sm")
stream = [{"text": "Hello world"}, {"text": "Another text"}]
stream = add_tokens(nlp, stream, skip=True)
fetch_media functionNew: 1.10
Replace all media paths and URLs in a stream with base64 data URIs. Can be used
for converting streams of image or audio files. The skip keyword argument lets
you specify whether to skip invalid files that can’t be converted (for example,
because the path doesn’t exist, or the URL can’t be fetched). If set to False,
Prodigy will raise a ValueError if it encounters invalid files.
| Argument | Type | Description |
|---|---|---|
stream | iterable | The stream of examples. |
input_keys | list | The task keys containing the media, e.g. ["image"] or ["audio", "video"]. |
skip | bool | Skip conversion for tasks with files that can’t be fetched. Defaults to False, which will raise a ValueError. |
| YIELDS | dict | The annotation examples with converted data. |
from prodigy.components.preprocess import fetch_media
stream = [{"image": "/path/to/image.jpg"}, {"image": "https://example.com/image.jpg"}]
stream = fetch_media(stream, ["image"], skip=True)
make_ner_suggestions functionNew: 1.13.1
Adds the named entity annotations suggestions from an nlp model to the stream.
Can be used with any spaCy nlp pipeline that has a component that can provide
NER suggestions. This includes spacy-llm pipelines.
In general you’ll want to make sure that you apply add_tokens
to the stream after adding the spans. This ensures that the token information is
attached to the spans as well.
import spacy
from prodigy.components.stream import get_stream
from prodigy.preprocess import make_ner_suggestions, add_tokens
nlp = spacy.load("en_core_web_md")
stream = get_stream("/path/to/examples.jsonl")
# Apply predictions
stream.apply(
make_ner_suggestions,
stream=stream,
nlp=nlp,
component="ner",
labels=["PERSON"],
)
# Make sure tokens are added everywhere, including in span annotations
stream.apply(add_tokens)
| Argument | Type | Description |
|---|---|---|
stream | iterable | The stream of examples. |
nlp | Language | A spaCy nlp object with a NER component. |
component | str | Name of the component in the nlp pipeline that supplies NER predictions |
labels | list | List of strings that represent the entity labels |
batch_size | int | Optional batch size for the spaCy model |
show_progress_bar | bool | Display a progress bar |
progress_bar_total | bool | Supply a pre-calculated total for the progress bar |
| YIELDS | dict | The annotation examples with converted data. |
make_spancat_suggestions functionNew: 1.13.1
Adds the spancat annotations suggestions from an nlp model to the stream. Can
be used with any spaCy nlp pipeline that has a component that can provide
spancat suggestions. This includes spacy-llm pipelines.
In general you’ll want to make sure that you apply add_tokens
to the stream after adding the spans. This ensures that the token information is
attached to the spans as well.
Examplepseudocode import spacy
from prodigy.components.stream import get_stream
from prodigy.preprocess import make_spancat_suggestions, add_tokens
nlp = spacy.load("model_with_spans")
stream = get_stream("/path/to/examples.jsonl")
# Apply predictions
stream.apply(
make_spancat_suggestions,
stream=stream,
nlp=nlp,
component="spancat",
labels=["LABEL_1", "LABEL_2"],
)
# Make sure tokens are added everywhere, including in span annotations
stream.apply(add_tokens)
| Argument | Type | Description |
|---|---|---|
stream | iterable | The stream of examples. |
nlp | Language | A spaCy nlp object with a spancat component. |
component | str | Name of the component in the nlp pipeline that supplies spancat predictions |
labels | list | List of strings that represent the entity labels |
batch_size | int | Optional batch size for the spaCy model |
show_progress_bar | bool | Display a progress bar |
progress_bar_total | bool | Supply a pre-calculated total for the progress bar |
| YIELDS | dict | The annotation examples with converted data. |
make_textcat_suggestions functionNew: 1.13.1
Adds the textcat predictions from an nlp model to the stream. Can be used with
any spaCy nlp pipeline that has a component that can provide NER suggestions.
This includes spacy-llm pipelines.
Examplepseudocode import spacy
from prodigy.components.stream import get_stream
from prodigy.preprocess import make_textcat_suggestions
nlp = spacy.load("model_with_textcat")
stream = get_stream("/path/to/examples.jsonl")
# Apply predictions
stream.apply(
make_textcat_suggestions,
stream=stream,
nlp=nlp,
component="textcat",
threshold=0.65
labels=["LABEL_1", "LABEL_2"],
)
# Make sure tokens are added everywhere, including in span annotations
stream.apply(add_tokens)
| Argument | Type | Description |
|---|---|---|
stream | iterable | The stream of examples. |
nlp | Language | A spaCy nlp object with a textcat or textcat_multilabel component. |
component | str | Name of the component in the nlp pipeline that supplies spancat predictions |
labels | list | List of strings that represent the entity labels |
threshold | float | Set the minimum confidence threshold needed to make a prediction |
batch_size | int | Optional batch size for the spaCy model |
show_progress_bar | bool | Display a progress bar |
progress_bar_total | bool | Supply a pre-calculated total for the progress bar |
| YIELDS | dict | The annotation examples with converted data. |
Sorters
Sorters are helper functions that wrap a stream of (score, example) tuples,
(usually returned by a model), resort it and yield examples in the new order.
They’re available via prodigy.components.sorters.
All sorters follow the same API and take two arguments:
| Argument | Type | Description |
|---|---|---|
stream | iterable | The stream to sort. |
bias | float | Bias towards high or low scoring. |
| YIELDS | dict | Annotation examples. |
The following sorters are available and can be imported from
prodigy.components.sorters:
| Sorter | Description |
|---|---|
prefer_uncertain | Resort stream to prefer uncertain scores. |
prefer_high_scores | Resort the stream to prefer high scores. |
prefer_low_scores | Resort the stream to prefer low scores. |
The prefer_uncertain function also supports an additional keyword argument
algorithm, that lets you specify either "probability" or "ema"
(exponential moving average).
from prodigy.components.sorters import prefer_uncertain
def score_stream(stream):
for example in stream:
score = model.predict(example["text"])
yield (score, example)
stream = prefer_uncertain(score_stream(stream))
Filters
Filters are helper functions used across recipes that wrap a stream and filter
it based on certain conditions. They’re available via
prodigy.components.filters.
filter_empty function
Remove examples with a missing, empty or otherwise falsy value from a stream.
This filter can also be enabled by specifying an input_key argument on the
get_stream helper function.
from prodigy.components.filters import filter_empty
stream = [{"text": "test"}, {"image": "test.jpg"}, {"text": ""}]
stream = filter_empty(stream, key="text")
# [{'text': 'test'}]
| Argument | Type | Description |
|---|---|---|
stream | iterable | The stream of examples. |
key | str | The key in the annotation task to check, e.g. 'text'. |
skip | bool | Skip filtered examples. If set to False, a ValueError is raised. Defaults to True. |
| YIELDS | dict | Filtered annotation examples. |
filter_duplicates function
Filter duplicate examples from a stream. You can choose to filter by task, which
includes the input data as well as the added spans, labels etc., or by input
data only. This filter can also enabled by setting dedup=True on the
get_stream helper function.
from prodigy.components.filters import filter_duplicates
from prodigy import set_hashes
stream = [{"text": "foo", "label": "bar"}, {"text": "foo", "label": "bar"}, {"text": "foo"}]
stream = [set_hashes(eg) for eg in stream]
stream = filter_duplicates(stream, by_input=False, by_task=True)
# [{'text': 'foo', 'label': 'bar', '_input_hash': ..., '_task_hash': ...}, {'text': 'foo', '_input_hash': ..., '_task_hash': ...}]
stream = filter_duplicates(stream, by_input=True, by_task=True)
# [{'text': 'foo', 'label': 'bar', '_input_hash': ..., '_task_hash': ...}]
| Argument | Type | Description |
|---|---|---|
stream | iterable | The stream of examples. |
by_input | bool | Filter out duplicates of the same input data. Defaults to False. |
by_task | bool | Filter out duplicates of the same task data. Defaults to True. |
| YIELDS | dict | Filtered annotation examples. |
filter_inputs function
Filter out tasks based on a list of input hashes, referring to the input data.
Useful for filtering out already annotated tasks. To get the task hashes of one
or more datasets, you can use db.get_input_hashes(*dataset_names).
from prodigy.components.filters import filter_inputs
stream = [{"_input_hash": 5, "text": "foo"}, {"_input_hash": 9, "text": "bar"}]
stream = filter_inputs(stream, [1, 2, 3, 4, 5])
# [{'_input_hash': 9, 'text': 'bar'}]
| Argument | Type | Description |
|---|---|---|
stream | iterable | The stream of examples. |
input_ids | list | The input IDs to filter out. |
| YIELDS | dict | Filtered annotation examples. |
filter_tasks function
Filter out tasks based on a list of task hashes, referring to the input data
plus the added spans, label etc. Useful for filtering out already annotated
tasks and used by Prodigy’s built-in --exclude logic. To get the task hashes
of one or more datasets, you can use db.get_task_hashes(*dataset_names).
from prodigy.components.filters import filter_tasks
stream = [{"_task_hash": 5, "text": "foo"}, {"_task_hash": 9, "text": "bar"}]
stream = filter_tasks(stream, [1, 2, 3, 4, 5])
# [{'_task_hash': 9, 'text': 'bar'}]
| Argument | Type | Description |
|---|---|---|
stream | iterable | The stream of examples. |
task_ids | list | The task IDs to filter out. |
| YIELDS | dict | Filtered annotation examples. |
filter_seen_before functionNew: 1.13
Filter out tasks that you may have seen before.
from prodigy.components.filters import filter_tasks
stream_a = [{"_task_hash": 5, "text": "foo"}, {"_task_hash": 9, "text": "bar"}]
stream_b = [{"_task_hash": 5, "text": "foo"}, {"_task_hash": 10, "text": "buz"}]
stream = filter_seen_before(stream_a, stream_b, exclude_by="task")
# [{'_task_hash': 9, 'text': 'bar'}]
| Argument | Type | Description |
|---|---|---|
stream | iterable | The stream of examples. |
stream_cache | iterable | The stream of before-seen examples. |
exclude_by | str | How to exclude examples can be input (default) or task. |
| YIELDS | dict | Filtered annotation examples. |
Task routers
Task routers are Python functions that determine which annotator will annotate
each example in a stream. You can read the full guide to
learn more about how they work. Built-in routers (no_overlap, full_overlap
and route_average_per_task) are available via
config settings or programatically via routers module.
Importantly, the task_router component also accepts custom routers. Check the
task routing guide for example implementations.
no_overlap functionNew: 1.12
Route each example to a single annotator either by setting
"feed_overlap": false (default) in the Prodigy
config file or passing the router function as the
task_router component like so:
recipe.py (except)pseudocode import prodigy
from prodigy.components.routers import no_overlap
@prodigy.recipe(
"my-custom-recipe",
dataset=("Dataset to save answers to", "positional", None, str),
view_id=("Annotation interface", "option", "v", str)
)
def my_custom_recipe(dataset, view_id="text"):
# Load your own streams from anywhere you want
stream = load_my_custom_stream()
return {
"dataset": dataset,
"view_id": view_id,
"stream": stream,
"task_router": no_overlap
}
full_overlap functionNew: 1.12
Route each example to each annotator either by setting "feed_overlap": true in
the Prodigy config file or passing the router function
as the task_router component like so:
recipe.py (except)pseudocode import prodigy
from prodigy.components.routers import full_overlap
@prodigy.recipe(
"my-custom-recipe",
dataset=("Dataset to save answers to", "positional", None, str),
view_id=("Annotation interface", "option", "v", str)
)
def my_custom_recipe(dataset, view_id="text"):
# Load your own streams from anywhere you want
stream = load_my_custom_stream()
return {
"dataset": dataset,
"view_id": view_id,
"stream": stream,
"task_router": full_overlap
}
route_average_per_task functionNew: 1.12
Assign partial annotator overlap by specifying how many annotators need to see
each example on average. In line with the other built-in routers, this can be
set in the config file via annotations_per_task
setting or programmatically:
recipe.py (except)pseudocode import prodigy
from prodigy.components.routers import route_average_per_task
@prodigy.recipe(
"my-custom-recipe",
dataset=("Dataset to save answers to", "positional", None, str),
view_id=("Annotation interface", "option", "v", str)
)
def my_custom_recipe(dataset, view_id="text"):
# Load your own streams from anywhere you want
stream = load_my_custom_stream()
return {
"dataset": dataset,
"view_id": view_id,
"stream": stream,
"task_router": route_average_per_task(2.5)
}
| Argument | Type | Description |
|---|---|---|
n | float | The number of annotators that need to see each example. |
| RETURNS | list | List of session ids to route a task to |
PatternMatcher
The PatternMatcher wraps spaCy’s
Matcher and PhraseMatcher and
will match both token-based and exact string match pattern on a stream of
incoming examples. It’s typically used in recipes like ner.teach or
textcat.teach to use
match pattern files to add suggestions. The
PatternMatcher can be updated with annotations and will score the individual
patterns. Patterns that are accepted more often will be scored higher than
patterns that are mostly rejected. Combined with a sorter, this lets
you focus on the most uncertain or the highest/lowest scoring patterns. The
pattern matcher is available via prodigy.models.matcher.
PatternMatcher.__init__ method
Initialize a pattern matcher.
from prodigy.models.matcher import PatternMatcher
import spacy
nlp = spacy.blank("en")
matcher = PatternMatcher(nlp)
| Argument | Type | Description |
|---|---|---|
nlp | spacy.language.Language | The spaCy language class to use for the matchers and to process text. |
label_span | bool | Whether to add a "label" to the matched span that’s highlighted. For example, if you use the matcher for NER, you typically want to add a label to the span but not the whole task. |
label_task | bool | Whether to add a "label" to the top-level task if a match for that label was found. For example, if you use the matcher for text classification, you typically want to add a label to the whole task. |
combine_matches | bool | New: 1.9 Whether to show all matches in one task. If False, the matcher will output one task for each match and duplicate tasks if necessary. |
all_examples | bool | New: 1.9.8 If True, all examples are returned, even if they don’t contain matches. If False (default), only examples with at least one match are returned. |
filter_labels | list | New: 1.9 Only add patterns if their labels are part of this list. If None (default), all labels are used. Can be set in recipes to make sure the matcher is only producing matches related to the specified labels, even if the file contains patterns for other labels. |
task_hash_keys | tuple | New: 1.9 Optional key names to consider for setting task hashes to prevent duplicates. For instance, only hashing by "label" would mean that "spans" added by the pattern matcher wouldn’t be considered for the hashes. |
prior_correct | float | Initial value of a pattern’s accepted count. Defaults to 2.0. Modifying this value changes how much of an impact a single accepted pattern has on the overall confidence. |
prior_incorrect | float | Initial value of a pattern’s rejected count. Defaults to 2.0. Modifying this value changes how much of an impact a single accepted pattern has on the overall confidence. |
The PatternMatcher assigns a confidence score to examples based on how many
examples matching that pattern have been accepted and rejected. The calculation
for this is:
score = (n_accept + prior_correct) / ((n_reject + prior_incorrect) / (n_accept + prior_correct))
Let’s say you’re working on a problem with imbalanced classes and you expect
that only about 5% of your examples will be accepted in your data. If an example
matches a pattern, there’s definitely a higher chance it will be accepted – but
the chances still aren’t that high. Let’s say matching examples have about a 20%
chance of being accepted. If the matching score was something like
n_accept / (n_accept + n_reject), then if you had a pattern that you’d
accepted once and rejected once, the scores would come out that examples
matching that pattern had a 50% chance of being accepted. But you know that’s
not actually likely – it’s probably not a great pattern that’s a huge indicator
of acceptance. It’s just that you haven’t seen many examples of it yet. You have
a prior belief about the distribution of positive and negative examples, and you
haven’t seen enough evidence from this pattern to really alter your beliefs.
The prior_correct and prior_incorrect settings let you represent how many
examples you expect to be accepted, and also how confident you are in that
belief. If you want each example of a pattern match to only change your prior
probability a little, you can set high absolute values on the priors – for
instance, setting prior_correct to 10.0 and prior_incorrect to 90.0
means the first example you see will only change the score by about 1%. If you
set them to 1.0 and 9.0, the score would change by about 10% instead.
PatternMatcher.__call__ method
Process a stream of examples and add pattern matches. Will add an entry to the
example dict’s "spans" for each match. Each span includes a "pattern" key,
mapped to the ID of the pattern that was used to produce this match. This is
also later used in PatternMatcher.update.
| Argument | Type | Description |
|---|---|---|
stream | iterable | The stream of examples to match on. |
batch_size | int | New: 1.10.8 The batch size to use when processing the examples. Defaults to 32. |
| YIELDS | tuple | The (score, example) tuples. |
PatternMatcher.from_disk method
Load patterns from a patterns file.
matcher = PatternMatcher(nlp).from_disk("./patterns.jsonl")
| Argument | Type | Description |
|---|---|---|
path | str / Path | The JSONL file to load the patterns from. |
| RETURNS | PatternMatcher | The updated matcher. |
PatternMatcher.add_patterns method
Add patterns to the pattern matcher.
patterns = [
{"label": "FRUIT", "pattern": [{"lower": "goji"}, {"lower": "berry"}]}
{"label": "VEGETABLE", "pattern": "Lamb's lettuce"}
]
matcher.add_patterns(patterns)
| Argument | Type | Description |
|---|---|---|
patterns | list | The patterns. Expects a list of dictionaries with the keys "pattern" and "label". See the patterns format for details. |
PatternMatcher.update method
Update the pattern matcher from annotation and update its scores. Typically
called as part of a recipe’s update callback and with answers received from
the web app. Expects the examples to have an "answer" key ("accept",
"reject" or "ignore") and will use all "spans" that have a "pattern"
key, which is the ID of the pattern assigned by
PatterMatcher.__call__.
answers = [
{
"text": "Hello Apple",
"spans": [{"start": 0, "end": 11, "label": "ORG", "pattern": 0}],
"answer": "reject"
}
]
matcher.update(answers)
| Argument | Type | Description |
|---|---|---|
examples | list | The annotated examples with accept/reject annotations. |
| RETURNS | int | Always 0 (only for compatibility with other annotation models that return a loss). |
Utility functions
combine_models function
Combine two models and return a predict and update function. Predictions of
both models are combined using the toolz.interleave function. Requires both
model objects to have a __call__ and an update() method. This helper
function is mostly used to combine annotation models with a PatternMatcher to
mix pattern matches and model suggestions. For an example, see the docs on
custom text classification models.
from prodigy.util import combine_models
from prodigy.models.matcher import PatternMatcher
class CustomModel:
def __call__(self, stream):
yield from predict_something(stream)
def update(self, answers):
update_something(answers)
predict, update = combine_models(CustomModel, PatternMatcher)
| Argument | Type | Description |
|---|---|---|
one | callable | First model. Requires a __call__ and update method. |
two | callable | Second model. Requires a __call__ and update method. |
batch_size | int | The batch size to use for predicting the stream. |
| RETURNS | tuple | A (predict, update) tuple of the respective functions. |
b64_to_bytes function
Convert a base64-encoded data URI to bytes. Can be used to convert the inlined
base64 "image", "audio" or "video" values annotation tasks to byte strings
that can be consumed by models. See the docs on
integrating image models for examples.
from prodigy.util import b64_to_bytes
image = "data:image/jpeg;base64,/9j/4AAQSkZJRgABAQEASABIA..." # and so on
image_bytes = b64_to_bytes(image)
| Argument | Type | Description |
|---|---|---|
data_uri | str | The data URI to convert. |
| RETURNS | bytes | The bytes data. |
file_to_b64 function
Convert a file to a base64-encoded data URI. Used under the hood by the media loaders.
from prodigy.util import file_to_b64
b64_str = file_to_b64("/path/to/image.jpg")
| Argument | Type | Description |
|---|---|---|
file_path | str / Path | The file path. |
mimetype | str | Optional MIME type. Will be guessed if not set. |
| RETURNS | str | The encoded base64 string. |
bytes_to_b64 function
Convert a bytestring to a base64-encoded data URI. Used under the hood by the media loaders.
from prodigy.util import bytes_to_b64
image_bytes = open("/path/to/image.jpg", "r").read()
b64_str = bytes_to_b64(image_bytes, "image/jpeg")
| Argument | Type | Description |
|---|---|---|
data | bytes | The bytes data. |
mimetype | str | The MIME type. |
| RETURNS | str | The encoded base64 string. |
split_string function
Split a comma-separated string and strip whitespace. A very simple utility that’s mostly used as a converter function in the recipe argument annotations to convert labels passed in from the command line.
from prodigy.util import split_string
assert split_string("PERSON,ORG,PRODUCT") == ["PERSON", "ORG", "PRODUCT"]
| Argument | Type | Description |
|---|---|---|
text | str | The text to split. |
| RETURNS | list | The split text or empty list if text is falsy. |
get_labels function
Utility function used in recipe argument annotations to handle command-line arguments that can either take a comma-separated list of labels or a file with one label per line. If the string is a valid file path, the file contents are read in line by line. Otherwise, the string is split on commas.
from prodigy.util import get_labels
assert get_labels("PERSON,ORG,PRODUCT") == ["PERSON", "ORG", "PRODUCT"]
assert get_labels("./labels.txt") == ["SOME", "LABELS", "FROM", "FILE"]
| Argument | Type | Description |
|---|---|---|
labels_data | str | The value passed in from the command line. |
| RETURNS | list | The list of labels read from a file or the string, or empty list if labels_data is falsy. |
Controller
The controller takes care of putting the individual recipe components together
and exposes methods that allow the application to interact with the REST API.
This is usually done when you use the @recipe decorator on a function that
returns a dictionary of components. However, you can also choose to initialize a
Controller yourself and make your recipe return it.
Controller.from_components classmethodNew: 1.11.8
Initialize a controller from the dictionary of components returned by a recipe function.
from prodigy.core import Controller
components = your_recipe("dataset", some_argument="some value")
controller = Controller.from_components("your_recipe", components)
| Argument | Type | Description |
|---|---|---|
name | str | The name of the recipe. |
components | dict | The dictionary of components returned by the recipe. |
config_overrides | dict | Optional overrides for the Prodigy config (e.g. from prodigy.json). |
Controller.__init__ method
Initialize the controller.
from prodigy.core import Controller
controller = Controller(dataset, view_id, stream, update, db,
progress, on_load, on_exit, before_db,
validate_answer, get_session_id, exclude,
config, None)
| Argument | Type | Description |
|---|---|---|
dataset | str | The ID of the current project. |
view_id | str | The annotation interface to use. |
stream | iterable | The stream of annotation tasks. |
update | callable | The update function called when annotated tasks are received. |
db | callable | The database ID, component or custom storage function. |
progress | callable | The progress function that computes the annotation progress. |
on_load | callable | The on load function that gets called when Prodigy is started. |
on_exit | callable | The on exit function that gets called when the user exits Prodigy. |
before_db | callable | Function called on examples before they’re placed in the database. |
validate_answer | callable | Function called on each answer to validate it and raise custom errors. |
get_session_id | callable | Function that returns a custom session ID. If not set, a timestamp is used. |
exclude | list | List of dataset IDs whose annotations to exclude. |
config | dict | Recipe-specific configuration. |
metrics | callable | Internals-only. |
| RETURNS | Controller | The recipe controller. |
All arguments of the controller are also accessible as attributes, for example
controller.dataset. In addition, the controller exposes the following
attributes:
| Argument | Type | Description |
|---|---|---|
home | Path | Path to Prodigy home directory. |
session_id | str | ID of the current session, generated from a timestamp. |
batch_size | int | The number of tasks to return at once. Taken from config and defaults to 10. |
queue | generator | The batched-up stream of annotation tasks. |
total_annotated | int | Number of tasks annotated in the current project. |
session_annotated | int | Number of tasks annotated in the current session (includes all named users in the instance). |
session_ids | set | New: 1.12.0 IDs of all named sessions that have connected to the current instance. |
session_annotated_by_session | dict | New: 1.10 Number of tasks annotated in the current session, keyed by ID of named sessions. |
Controller.get_questions method
Get a batch of annotation tasks from the queue.
next_batch = controller.get_questions()
| Argument | Type | Description |
|---|---|---|
session_id | str | Optional ID of named session, defaults to None. |
excludes | list | Optional list of task hashes to not send, e.g. that are already out for annotation. This is used to control what to re-send if "force_stream_order" config is set to True. Defaults to None. |
| RETURNS | list | Batch of annotation tasks. |
Controller.receive_answers method
Receive a batch of annotated tasks. If available, stores the tasks in the
database and calls the update function.
tasks = [
{"_input_hash": 0, "_task_hash": 0, "text": "x", "answer": "accept"},
{"_input_hash": 1, "_task_hash": 1, "text": "y", "answer": "reject"}
]
controller.receive_answers(tasks)
| Argument | Type | Description |
|---|---|---|
answers | list | Annotated tasks. |
session_id | str | Optional ID of named session, defaults to None. |
Controller.save method
Saves the current project and progress when the user exits the application. If
available, calls the store’s save method and the on_exit function.
Controller.get_total_by_session methodNew: 1.10
Get the total number of examples available in the dataset for a given named session.
| Argument | Type | Description |
|---|---|---|
session_id | str | ID of the named session. |
| RETURNS | int | The number of annotations. |
Controller.progress property
Get the current progress. If available, calls the progress function. Otherwise, it checks whether the stream has a length and returns the quotient of the session annotations and stream length. Otherwise, it returns None. A progress of None is visualized with an infinity symbol in the web application.
Controller.get_progress New: 1.12
| Argument | Type | Description |
|---|---|---|
session_id | str or None | ID of the named session. |
| RETURNS | float or None | The current annotation progress. |
Get the current progress for a specific session_id. If available, calls the
progress function provided to the Controller. If not, the Controller has a few
default Progress estimators it will choose from based on other Controller
settings.
- If an
updatecallback is provided, a progress estimator will be used that has been in Prodigy since the beginning for active learning workflows. It assumes the return value ofupdaterepresents a loss value and will use gradient descent to estimate when model in the loop has enough annotations (visualised asPROGRESSin the web app).
-
If no
updatecallback is provided but thetotal_examples_targetconfig variable is set, the progress is the quotient of the number of saved examples for this session and the value oftotal_examples_target(visualised asTARGET PROGRESSin the web app). -
If no
updatecallback is provided and thetotal_examples_targetconfig variable is not set, progress is estimated (and in some cases calculated) as the quotient of theSourceposition and its size (visualised asSOURCE PROGRESSin the web app).
For the best annotator experience, we recommend setting a
total_examples_target value. The progress bar will be the most accurate when
this is set.
You can also always provide a
custom progress function via the "progress"
component to the dictionary of Recipe components returned by your custom recipe.
def progress(ctrl, update_return_value):
return ctrl.session_annotated / 2500
@prodigy.recipe(
"example",
dataset=("Dataset to save annotations to", "positional", None, str),
source=("Source data to load", "positional", None, str),
view_id=("Annotation interface to use", "option", "v", str)
)
def example(dataset, source, view_id="text"):
stream = get_stream(source)
return {
"dataset": dataset,
"view_id": view_id,
"stream": stream,
"progress": progress
}
Under the hood, Prodigy has a few abstractions to separate the different concerns of the application.
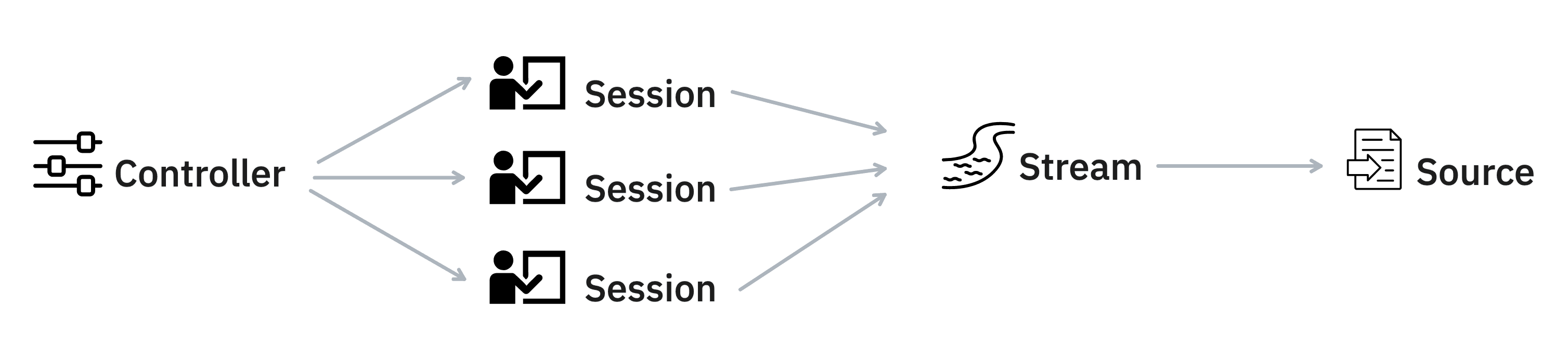
-
The
Controllermakes sure that all the settings are parsed correctly and can be seen as the central object that deligates tasks to other objects. -
The
Sessionrepresents a user session during which data will get annotated. If multiple annotators are annotating then they can be identified by the name that is passed via/?session=. Anynomous annotations will get assigned a session that is denoted by the creation timestamp. -
The
Streamrepresents the stream of data that still needs to be annotated. The stream maintains a queue of examples for each session. This way, we have a single place where task routing might occur. -
The
Sourcerepresents the original data source for the stream. This may refer to a file on disk but can also refer to a set of files or to a Prodigy dataset.
The Source object can represent a file on disk together with a read position.
This file will have a known size upfront. That means that whenever a new block
of data is read from the file the read position can update, allowing us to to
estimate the annotation progress. However, because this estimate is only aware
of the current position in the Source it is not aware of anything that’s
happening in the Stream or Controller objects.
This offers a tractable way to estimate progress, but it has a few consequences that can be unintuitive in multiuser scenarios.
- The
Source-based progress tracks the progress through the input file rather than completed annotations. This means that even when starting a single-annotator flow, there will already be a non-zero progress as some of the file will have been consumed in the process of session initialization. - It is possible for one annotator to reach the end of their queue before the
rest does. When this happens, the
Sourcewill have a position at the end of the file. So theSource-based progress bar will show 100% to every annotator. - The
Sourceis unaware of the task router and the current sessions. Depending on the Prodigy configuration it could be possible for new annotators to join at given time. That also means that a person could join and immediately see a significant progress when they arrive at the annotation interface.
To prevent these scenarios, it may be more convenient to configure to set a
target via total_examples_target in
your prodigy.json file or to use
a custom progress callback.
If the Source has a known length, (e.g. a list of tasks or loading from a
Parquet file or a JSONL file) progress can be calculated exactly. When using
a file based source (e.g. loading a CSV file) progress is estimated by
calculating the size in bytes, reading the file in chunks and using the quotient
of byte offset and total bytes.
If none of these conditions are met, and the stream provided to the Controller
is a simple generator, this method returns None. A progress of None is
visualized with an infinity symbol in the web application.
| Argument | Type | Description |
|---|---|---|
| RETURNS | float or None | The current annotation progress. |
Controller.get_session_name New: 1.12
Get the appropriate session name for an annotator name. This method can be very useful when writing your own custom task routers when you want to make sure that you’re able to map a name to the appropriate session id.
| Argument | Type | Description |
|---|---|---|
name | str | Name of an annotator. |
| RETURNS | str | ID of the named session. |
Controller.confirm_session New: 1.12
Ensure that a session ID exists. This is useful in custom task routers when you want to add a task to a queue that might not have started annotating yet. More details on how this mechanic works can be found on the task routing documentation page. There’s a also a detailed example that shows a use-case for such a function here.
| Argument | Type | Description |
|---|---|---|
session_id | str | ID of the named session. |
| RETURNS | Session object | The session object that belongs to the session ID |
Controller.add_session New: 1.12
Add session to the controller’s internal list of available sessions. This is useful when custom session_factory is used.
| Argument | Type | Description |
|---|---|---|
session | Session | Initialized Session object. |
Controller.reset_stream New: 1.14.11
Reset the stream such that all sessions will get different examples to annotate. Meant to be used in custom event callbacks.
| Argument | Type | Description |
|---|---|---|
new_stream | Stream object | New stream to annotate. |
apply_wrappers | bool | Apply the wrappers of the original stream to the new one. |
Stream New: 1.12
Loads and transform items from a raw data source, and enqueues them to one or
more queues. Queues can be added during iteration and can be populated by any
number of items from the history. As of v1.12 the Stream type can be used
instead of the Generator type for the stream of annotations tasks. The Generator
based stream will be deprecated in Prodigy v2.0. Note that this function is
different from the old prodigy.get_stream
function, which would return a Generator.
stream.get_stream functionNew: 1.12
Get an iterable stream of tasks of Stream type. Under the hood it resolves the
input type so that in can be handled with the appropriate loader, unless a
custom loader is provided. If the source is set to "-", Prodigy will read
from standard input, letting you pipe data forward on the command line.
from prodigy.components.stream import get_stream
stream = get_stream("/tmp/data.jsonl")
stream = get_stream("/tmp/myfile.tmp", loader="txt")
stream = get_stream("/tmp/data.json", input_key="text", skip_invalid=False)
| Argument | Type | Description |
|---|---|---|
source | str | A data source, e.g. a file path or Prodigy dataset name (with dataset: prefix). Defaults to "-" for sys.stdin.New: 1.12 Also supports Parquet files. |
loader | str | ID of a loader, e.g. "json" or "csv". |
rehash | bool | Rehash the stream and assign new input and task IDs. |
dedup | bool | Deduplicate the stream and filter out duplicate input tasks. |
input_key | str | Optional input key relevant to this task, to filter out examples with invalid keys. For example, 'text' for NER and text classification projects and 'image' for image projects. |
skip_invalid | bool | If an input key is set, skip invalid tasks. Defaults to True. If set to False, a ValueError will be raised. |
is_binary | bool | Whether the annotations are of binary (accept/reject) type. |
| RETURNS | Stream | An iterable stream of tasks produced by the loader. |
stream.apply methodNew: 1.12
Transforms the stream of tasks by applying a function that returns a generator of tasks. Can be used for any preprocessing of the annotation tasks such as adding tokens, splitting sentences or defining tasks data structures from scratch.
def my_wrapper(nlp, stream):
for eg in stream:
eg["new_key"] = new_value
yield eg
stream.apply(my_wrapper, nlp, stream)
You can also import and use the special value STREAM_PLACEHOLDER to indicate
which argument is the stream:
from prodigy.stream import STREAM_PLACEHOLDER
def my_wrapper(arg1, arg2):
for eg in arg2:
eg["new_key"] = new_value
yield eg
stream.apply(my_wrapper, nlp, STREAM_PLACEHOLDER)
The same works for keyword arguments:
def my_wrapper(arg1, arg2, *, arbitrary_name):
for eg in arbitrary_name:
eg["new_key"] = new_value
yield eg
stream.apply(my_wrapper, arg1, arg2, arbitrary_name=stream)
If the stream instance is not in the args or kwargs, it is assumed to be the first argument to the wrapper.
| Argument | Type | Description |
|---|---|---|
wrapper | callable | A function to apply to the elements of the stream |
*args | any | Positional arguments to the wrapper. |
*kwargs | any | Keyword arguments to the wrapper. |
| RETURNS | Stream | An iterable stream of tasks. |
Session New: 1.12
The session represents the Prodigy annotator session with a queue of tasks to pull from and the temporary buffer of pulled but unanswered tasks. It also exposes a number of attributes relevant to history tracking and progress estimation. A new session is initialized every time a user accesses the Prodigy server with a URL. As of v1.12 this initialization can be customized by providing session_factory callback to the Controller.
Session.__init__ methodNew: 1.12
Initialize the session object.
from prodigy.components import Session
session = Session(session_id, stream, batch_size, answered_input_hashes, answered_task_hashes,
total_annotated, target_annotated)
| Argument | Type | Description |
|---|---|---|
session_id | str | The ID of the session to be initialized. |
stream | iterable | The stream of annotation tasks. |
batch_size | int | The number of tasks to return at once. |
answered_input_hashes | set | Optional set of input hashes that has already been answered by this session and should thus be excluded from the queue. |
answered_task_hashes | set | Optional set of task hashes that has already been answered by this session and should thus be excluded from the queue. |
total_annotated | int | Optional value for the total of annotations done. Defaults to 0. |
target_annotated | int | Optional value for the target of annotations to be done. Defaults to 0. |
| RETURNS | Session | The session object. |
All arguments of the session are also accessible as attributes, for example
session.total_annotated. In addition, the session exposes the following
attributes:
| Argument | Type | Description |
|---|---|---|
progress | float | The estimation of the progress through the annotation task. |
timestamp | float | The timestamp of when the session was last accessed. |
batch_size | int | The number of tasks to return at once. Taken from config and defaults to 10. |